
Publié le 16/02/2025
Par Johan Coureuil
1. Comprendre le stockage des données dans SQL Server
Avant de parler des index et de leur fragmentation, il est crucial de comprendre comment SQL Server stocke les données dans ses fichiers (.mdf).
1.1. Les fichiers MDF et l’unité de stockage : la page
SQL Server stocke les données dans des fichiers MDF (Primary Data File) et utilise une structure interne basée sur des pages de 8 Ko. Chaque table et chaque index sont constitués de ces pages.
Un ensemble de 8 pages consécutives forme une étendue (extent), qui peut être soit :
- Uniforme (uniform extent) : allouée entièrement à un seul objet.
- Mixte (mixed extent) : partagée entre plusieurs objets (principalement pour optimiser l’espace).
1.2. La structure en B-Tree et le niveau des feuilles (Leaf Level)
Les données et les index sont organisés sous forme d’arbre B (B-Tree) :
- Niveau racine (Root Level) : Contient un pointeur vers les pages intermédiaires.
- Niveaux intermédiaires : Permettent de naviguer rapidement dans l’arbre.
- Niveau des feuilles (Leaf Level) : Contient soit les données réelles (pour un index clusterisé) soit des pointeurs vers les données (pour un index non-clusterisé).
Exemple visuel simplifié d’un B-Tree :
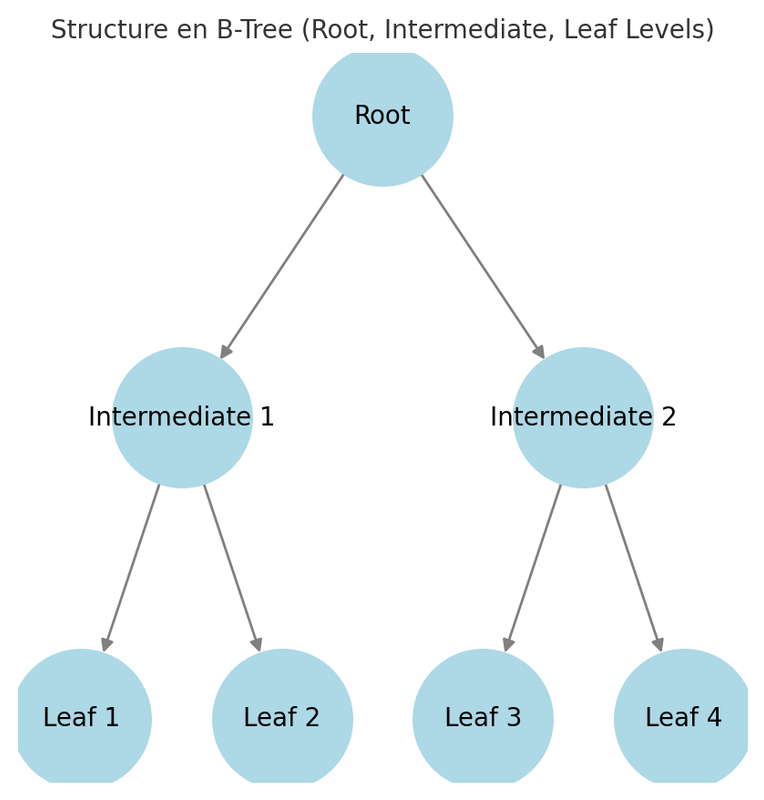
Plus la profondeur de l’arbre est faible, plus les recherches sont rapides. C’est là que la fragmentation peut devenir un problème, car elle impacte la structure de cet arbre.
2. Qu’est-ce qu’un index et comment fonctionne-t-il ?
Un index est une structure qui accélère la recherche de données en permettant des accès directs plutôt qu’un scan séquentiel.
2.1. Les types d’index en SQL Server
Il existe plusieurs types d’index :
- Clustered Index : Trie physiquement les données sur le disque en fonction de la clé d’indexation.
- Non-Clustered Index : Stocke uniquement des pointeurs vers les données.
- Filtered Index : Index partiel sur un sous-ensemble de données.
- Columnstore Index : Optimisé pour les requêtes analytiques.
Lien utile : Lire l’article sur les index couvrant
2.2. Algorithmes de recherche et accès aux données
SQL Server utilise des algorithmes comme Seek (recherche rapide via l’index) et Scan (parcours séquentiel) :
- Index Seek : Recherche ciblée et rapide dans un index.
- Index Scan : Parcours complet d’un index, coûteux en performances.
Une bonne structure d’index réduit les Index Scan et favorise les Index Seek.
A noter : Qu'il ne faut pas être obsedé par la recherche d'un Index Seek, ici il est juste expliqué la différence entre ces deux la uniquement, il existe plusieurs statut sur les recherches de données comme le Table Scan, l'index Lookup (...), mais il est hautement préférable que vous ayez ces deux là, on parle d'unité de mesure de l'ordre de la nanoseconde.
3. La fragmentation : quand votre index devient un puzzle
3.1. Définition de la fragmentation
La fragmentation se produit lorsque les pages d’index ne sont plus contiguës ou ordonnées correctement, ralentissant les requêtes.
Il existe deux types de fragmentation :
- Fragmentation Interne : Trop d’espace inutilisé dans les pages (ex : remplissage à 50%).
- Fragmentation Externe : Pages dispersées et non séquentielles.
3.2. Causes principales de la fragmentation
- INSERT / UPDATE / DELETE : Un volume élevé de modifications désorganise les pages.
- Auto-Growth mal configuré : Des fichiers qui s’agrandissent trop souvent en petits morceaux.
- Mauvais Fill Factor : Un paramètre d’index mal ajusté entraîne des pages remplies à moitié.
3.3. Conséquences sur la performance
- Augmentation du nombre de lectures disque (I/O élevé).
- Réduction de l’efficacité du cache mémoire.
- Ralentissement des requêtes utilisant des Index Seek.
4. Impact des types de données sur l’indexation et la fragmentation
4.1. Liste des types de données et leurs tailles
| Type | Taille (Octets) | Description |
|---|---|---|
TINYINT |
1 | Entier de 0 à 255 |
SMALLINT |
2 | Entier de -32,768 à 32,767 |
INT |
4 | Entier de -2,147,483,648 à 2,147,483,647 |
BIGINT |
8 | Très grands nombres entiers |
CHAR(N) |
N | Chaîne de longueur fixe |
VARCHAR(N) |
Variable | Chaîne de longueur variable |
TEXT |
Déprécié | À éviter au profit de VARCHAR(MAX) |
DECIMAL(P,S) |
Variable | Nombre décimal avec précision |
4.2. Pourquoi le choix du type de données est crucial
- Impact sur la taille des index : Un
BIGINTprend 8 octets alors qu’unINTen prend 4. - Réduction du nombre de pages nécessaires : Un type trop large gaspille de l’espace et augmente la fragmentation.
- Alignement avec les besoins métier : Utiliser un
VARCHAR(255)au lieu d’unVARCHAR(50)peut être inutilement coûteux.
Conclusion
Nous avons exploré en profondeur :
- Le stockage SQL Server et son organisation en pages.
- Le fonctionnement des index et leur impact sur les performances.
- La fragmentation, ses causes et conséquences.
- L’importance du choix des types de données pour optimiser le stockage et réduire la fragmentation.
Moralité ? Un bon index est comme une étagère bien rangée : il faut éviter l’encombrement et garder tout bien ordonné pour une recherche rapide et efficace !

Johan Coureuil
Développeur Back-End C# .NET & DBA SQL Server