
Publié le 15/05/2023
Par Alexandre CASTRO
Aujourd'hui nous nous retrouvons pour un tutoriel sur les bases du machine learning.
J'ai eu l'occasion de travailler sur des projets avec des services de machine learning ou d'IA (sur étagère comme Cognitives Services , Chat GTP etc ) ou même en lien avec des services de machine learning custom et j'ai du m'acculturer en tant que développeur à ces technologies.
Par la suite j'ai passé la certification AI-900 afin de vérifier mes connaissances sur les sujet et surtout acquérir les mots clé de cette disciple. D'ailleurs c'est un learning path et une certification que je recommande vivement car cela m'a permis de comprendre beaucoup de choses.
Ensuite j'ai décidé de regarder ce que Microsoft proposait pour l'IA et j'ai vu qu'il y avait la partie ML.NET et je me suis donc naturellement penché vers ce framework en tant que développeur .NET.
Evidemment les puristes vous diront que j'aurais du faire du python, mais personnellement je voulais regarder ce que valait ce framework avec mes petites bases en IA et surtout en termes d'accessibilité pour les développeurs .NET.
Nous allons commencer par créer un projet console qui permettra d'illustrer les concepts de machine learning par la suite.
Dans mon projet console je vais intégrer un fichier csv avec des données démographiques comme l'âge, le sexe ou le statut marital qui va me servir de base pour mon modèle.
Le mode assisté "WYSIWYG"
Nous allons commencer par le setup "WYSIWYG" en ajoutant un modèle de données :
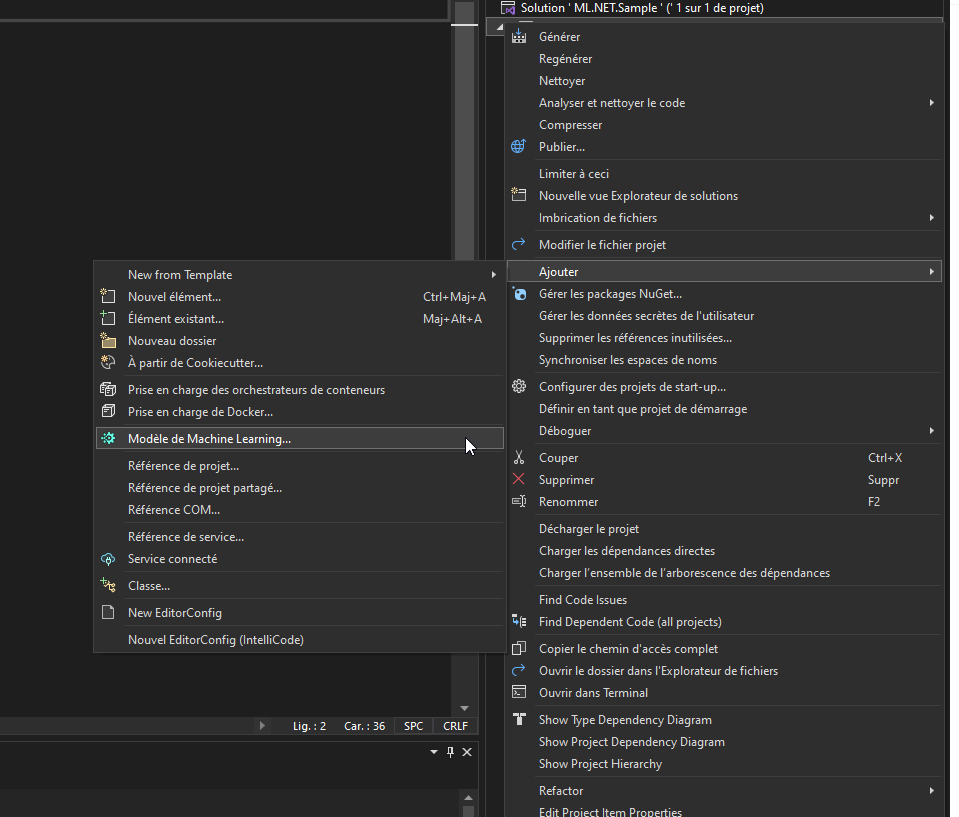
Ensuite choisissons un modèle de classification binaire (binary classification) qui va nous permettre de prédire si la personne achèterait selon des données démographiques: 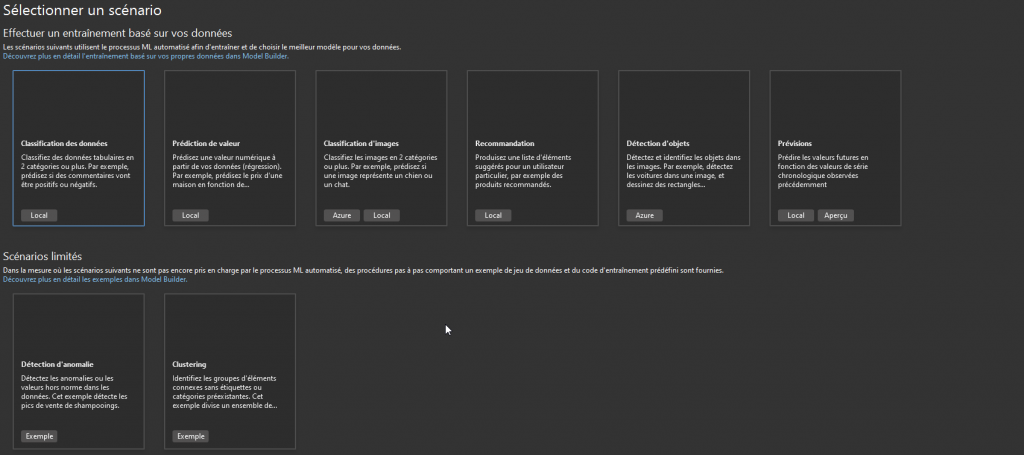
En environnement local : 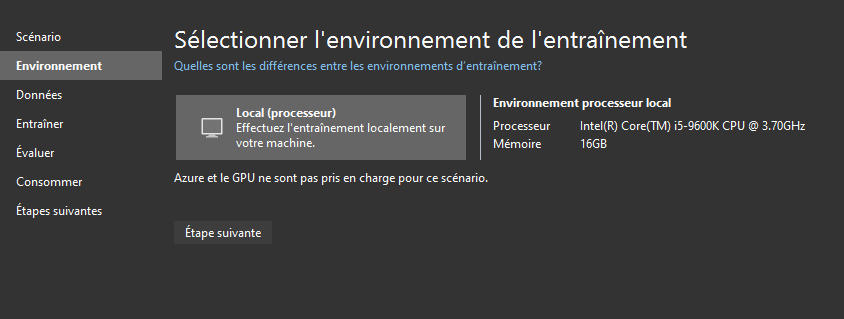
Vous chargez vos données et ensuite choisissez la colonne à prédire :
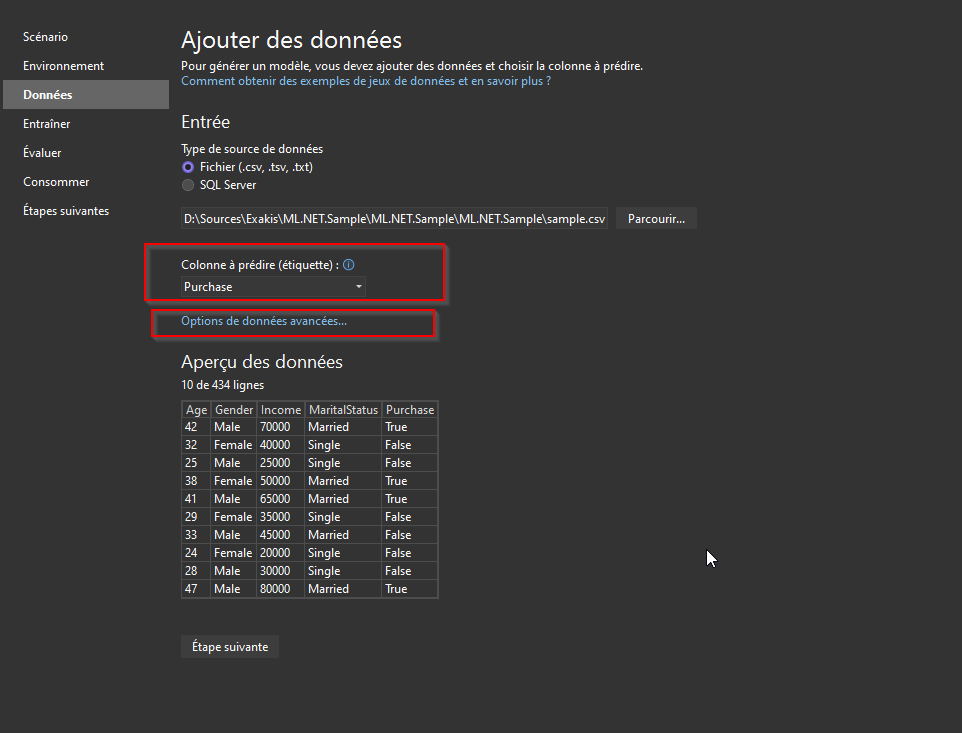
Et dans les données avancées, choisissez les colonnes qui serviront à la prédiction :
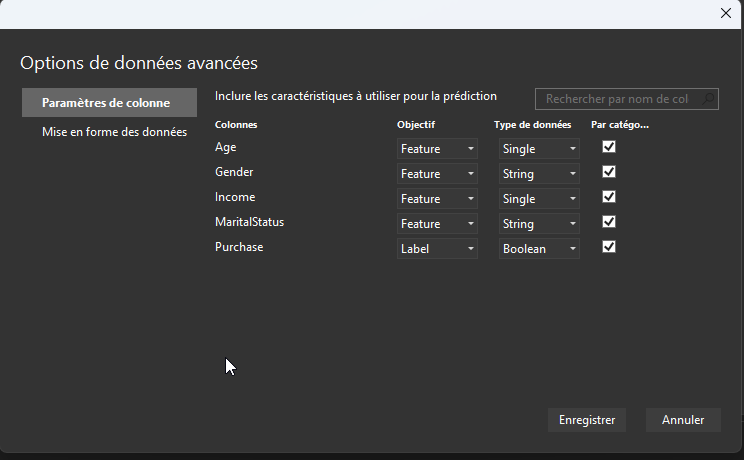
Les colonnes qui servent à la prédiction sont les "features" et la colonne prédite est le "label".
Les features sont les variables d'entrée ou les attributs des données qui sont utilisés pour faire des prédictions. Ils peuvent être considérés comme les variables indépendantes d'un modèle d'apprentissage automatique(Hypothèse de base à la plupart des problèmes de machine learning. Une dépendance inter variables incluent une modifications des méthodes statistiques/mathématiques utilisée). Des exemples de features peuvent inclure l'âge, le revenu, le niveau d'éducation ou le code postal d'une personne. Les fonctionnalités peuvent être des données numériques, catégorielles ou textuelles et peuvent nécessiter un prétraitement avant de pouvoir être utilisées dans un modèle d'apprentissage automatique.
le Label est la variable de sortie que nous voulons prédire en fonction des entités d'entrée. L'étiquette peut être considérée comme la variable dépendante dans un modèle d'apprentissage automatique. Des exemples de labels peuvent inclure si une personne est susceptible d'acheter un produit ou non, si un e-mail est un spam ou non, ou le prix d'une maison. Les labels peuvent être binaires (par exemple, vrai/faux), multi-classes (par exemple, rouge/vert/bleu) ou continues (par exemple, valeur numérique).
Dans un modèle d'apprentissage automatique, l'objectif est d'utiliser les caractéristiques d'entrée pour prédire le label de sortie. Le processus de formation d'un modèle d'apprentissage automatique implique de trouver la relation entre les features et les labels dans les données de formation et d'utiliser cette relation pour faire des prédictions sur de nouvelles données d’inférence non visibles lors de l’entrainement. Une fois le modèle formé, il peut être utilisé pour faire des prédictions sur de nouvelles données représentant les features en entrée et en sortir le label prédit.
Entrainez donc votre modèle :
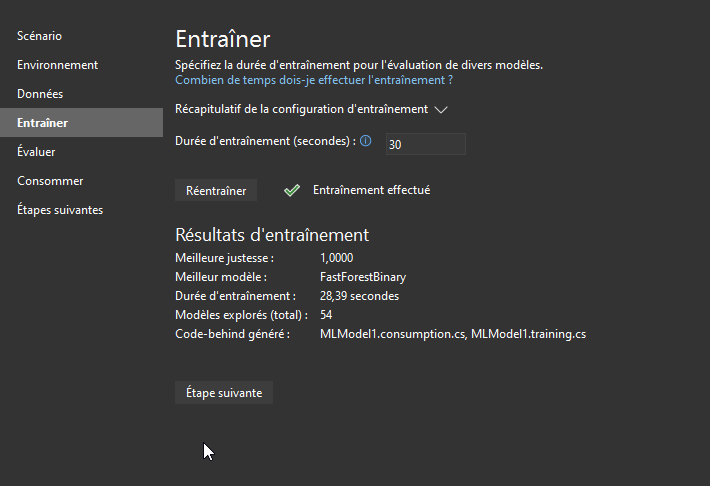
Et testez le 😉
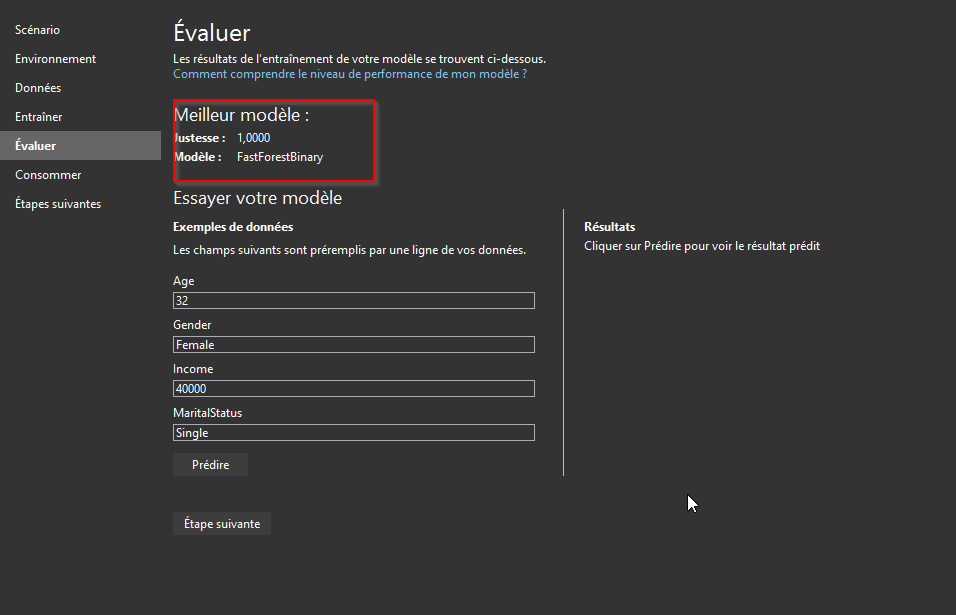
L'entrainement précédent a déterminé que le meilleur modèle algorithme de classification était le FastForestBinary avec une précision à 100% après 30 secondes d'entrainement !
Cette précision est liée au fait que le modèle soit « simpliste » et orienté car dans un cas concret réel, ce type de résultats pourrait faire penser à un surentrainement qui par extension pourrait donner des résultats hasardeux lors des prédictions.
Pour finir on vous montre comment consommer ce modèle :
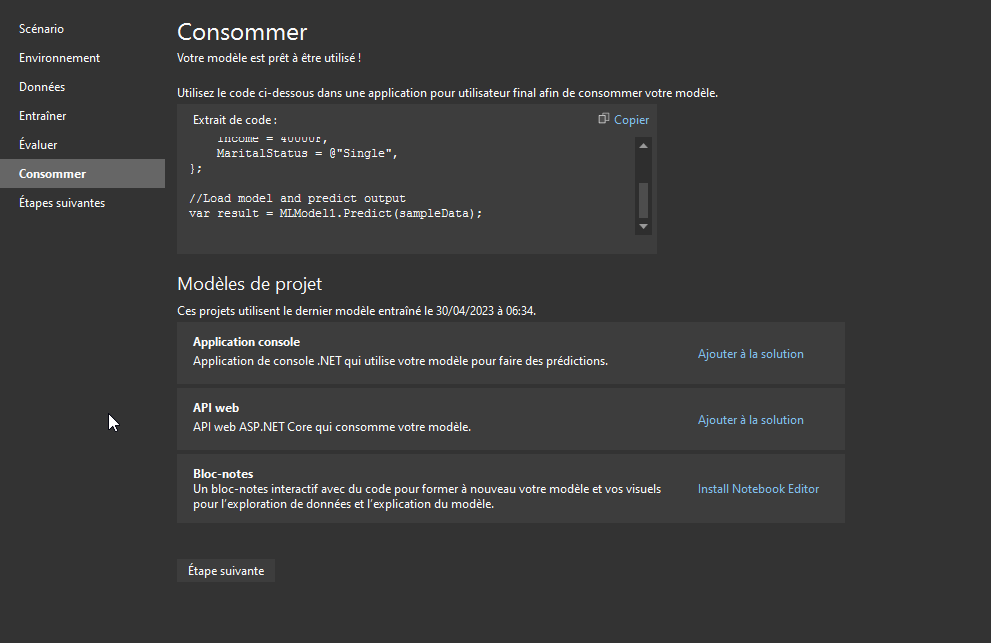
Et le déployer ou l'améliorer car oui en local c'est bien mais déployé pour le consommer c'est mieux mais ce n'est pas le but de cet article.
Ensuite dans notre application Console , nous avons juste à écrire cela :
//Load sample data
var sampleData = new MLModel1.ModelInput()
{
Age = 32F,
Gender = @"Female",
Income = 40000F,
MaritalStatus = @"Single",
};
//Load model and predict output
var result = MLModel1.Predict(sampleData);
Console.WriteLine(result.Purchase);
Et observons le résultat :
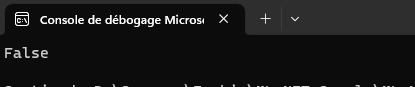
En 5 minutes vous avez créé un modèle de classification qui fonctionne avec 100% de précision !
Le mode "à la main "
En dehors du mode "WYSIWYG", vous pouvez tout écrire en .NET afin de maitriser toutes les étapes
Pour cela nous allons créer une classe qui définira notre modèle à entrainer :
public class Customer
{
[LoadColumn(0)]
[ColumnName(@"Age")]
public float Age { get; set; }
[LoadColumn(1)]
[ColumnName(@"Gender")]
public string Gender { get; set; }
[LoadColumn(2)]
[ColumnName(@"Income")]
public float Income { get; set; }
[LoadColumn(3)]
[ColumnName(@"MaritalStatus")]
public string MaritalStatus { get; set; }
[LoadColumn(4)]
[ColumnName(@"Purchase")]
public bool Purchase { get; set; }
}Et une autre pour le résulat de notre prédiction :
Pour ces classes vous allez avoir besoin de ces 2 packages Nuget :
Et pour finir un peu de code :
var mlContext = new MLContext();
var dataFile = Path.Combine(Environment.CurrentDirectory,"sample.csv");
var modelFile = Path.Combine(Environment.CurrentDirectory,"model.mlnet");
// Load the data from a CSV file
var data = mlContext.Data.LoadFromTextFile<Customer>(path: dataFile,
separatorChar: ',',
hasHeader: true);
// Split the data into training and testing datasets
var split = mlContext.Data.TrainTestSplit(data, testFraction: 0.2);
var trainData = split.TrainSet;
var testData = split.TestSet;
// Define the machine learning pipeline
var pipeline = mlContext.Transforms.Categorical.OneHotEncoding(new[] { new InputOutputColumnPair(@"Age", @"Age"),
new InputOutputColumnPair(@"Income", @"Income"),
new InputOutputColumnPair(@"Gender", @"Gender"),
new InputOutputColumnPair(@"MaritalStatus", @"MaritalStatus"), },
outputKind: OneHotEncodingEstimator.OutputKind.Indicator)
.Append(mlContext.Transforms.Concatenate(@"Features", new[] { @"Gender", @"MaritalStatus", @"Age", @"Income" }))
.Append(mlContext.BinaryClassification.Trainers.FastTree(new FastTreeBinaryTrainer.Options() { NumberOfLeaves = 4, MinimumExampleCountPerLeaf = 20, NumberOfTrees = 4, MaximumBinCountPerFeature = 254, FeatureFraction = 1, LearningRate = 0.1, LabelColumnName = @"Purchase", FeatureColumnName = @"Features" }));
// Train the model
var model = pipeline.Fit(trainData);
// Evaluate the model on the testing dataset
var predictions = model.Transform(testData);
var metrics = mlContext.BinaryClassification.Evaluate(predictions, "Purchase");
Console.WriteLine($"Accuracy: {metrics.Accuracy:P2}");
//Save model to file
DataViewSchema dataViewSchema = data.Schema;
using (var fs = File.Create(modelFile))
{
mlContext.Model.Save(model, dataViewSchema, fs);
}
// Load model from file
mlContext.Model.Load(modelFile, out var _);
var predictionEngine = mlContext.Model.CreatePredictionEngine<Customer, Prediction>(model);
// Make a prediction on new data
var customer = new Customer { Age = 35, Gender = "Male", Income = 50000, MaritalStatus = "Single" };
var prediction = predictionEngine.Predict(customer);
Console.WriteLine($"Prediction: {prediction.Purchase}");Nous avons beaucoup d'informations ici mais au final nous avons fait exactement les mêmes étapes que lors de la configuration assistée.
Nous définissons d'abord la classe de modèle à entrainer, le chemin vers notre modèle puis le modèle de prédiction.
Ensuite nous définissons le pipeline d'apprentissage supervisé, qui comprend des transformations de données telles que l'encodage et le one hot encoding, et un modèle d'entrainement de classification binaire FastTree. Le pipeline prépare les données d'entrée pour l'entrainement du modèle de classification binaire et entraîne le modèle sur l'ensemble de données d'apprentissage.
L'application évalue ensuite les performances du modèle formé sur l'ensemble de données de test et imprime le score de précision. . Il enregistre le modèle entrainé dans un fichier et le recharge. Enfin, il utilise le modèle chargé pour faire une prédiction sur de nouvelles données et imprime la sortie prédite.
Cet exemple illustre le worklow de base de la création d'un modèle d'apprentissage supervisé personnalisé avec ML.NET, y compris le chargement des données, la transformation, la formation du modèle, l'évaluation et la prédiction. L'exemple utilise une variété de composants ML.NET, tels que Data.LoadFromTextFile, Data.TrainTestSplit, Transforms.Categorical.OneHotEncoding, Transforms.Concatenate, BinaryClassification.Trainers.FastTree, Model.Save, Model.Load et Model.CreatePredictionEngine.
L'aspect le plus difficile à comprendre est le processus de construction du pipeline.
// Define the machine learning pipeline
var pipeline = mlContext.Transforms.Categorical.OneHotEncoding(new[] { new InputOutputColumnPair(@"Age", @"Age"),
new InputOutputColumnPair(@"Income", @"Income"),
new InputOutputColumnPair(@"Gender", @"Gender"),
new InputOutputColumnPair(@"MaritalStatus", @"MaritalStatus"), },
outputKind: OneHotEncodingEstimator.OutputKind.Indicator)
.Append(mlContext.Transforms.Concatenate(@"Features", new[] { @"Gender", @"MaritalStatus", @"Age", @"Income" }))
.Append(mlContext.BinaryClassification.Trainers.FastTree(new FastTreeBinaryTrainer.Options() { NumberOfLeaves = 4, MinimumExampleCountPerLeaf = 20, NumberOfTrees = 4, MaximumBinCountPerFeature = 254, FeatureFraction = 1, LearningRate = 0.1, LabelColumnName = @"Purchase", FeatureColumnName = @"Features" }));
Comme nous l'avons vu dans l'exemple "assisté", il illustre très bien ce workflow :
- Chargement des données : la première étape consiste à charger les données dans un objet ML.NET IDataView. Vous pouvez charger des données à partir de diverses sources, telles que des fichiers CSV, des bases de données SQL ou des services Web.
- Prétraitement des données : Ensuite, vous devrez prétraiter les données pour les préparer à l'apprentissage automatique. Cela peut impliquer des tâches telles que le nettoyage et la transformation des données, la sélection des features pertinentes et la division des données en ensembles de données d'apprentissage et de test.
- Entraînement de modèle : une fois les données préparées, vous pouvez utiliser les algorithmes d'apprentissage automatique intégrés de ML.NET pour entraîner un modèle sur l'ensemble de données d'entraînement. ML.NET prend en charge un large éventail de scénarios d'apprentissage automatique, notamment la classification binaire, la classification multiclasse, la régression et le clustering.
- Évaluation du modèle : après avoir formé le modèle, vous souhaiterez évaluer ses performances sur l'ensemble de données de test pour voir dans quelle mesure il se généralise aux nouvelles données. ML.NET fournit une variété de mesures d'évaluation, telles que l'exactitude, la précision, le rappel et l'AUC, pour vous aider à évaluer les performances du modèle.
- Déploiement du modèle : une fois que vous êtes satisfait des performances du modèle, vous pouvez le déployer dans un environnement de production. ML.NET fournit diverses options de déploiement, notamment l'exportation du modèle au format ONNX, son enregistrement en tant que fichier binaire ou son déploiement en tant que service Web à l'aide d'Azure Machine Learning.
- Consommation de modèle : vous pouvez utiliser le modèle formé pour effectuer des prédictions sur de nouvelles données dans un environnement de production. ML.NET fournit diverses méthodes pour consommer le modèle formé, telles que l'utilisation de la classe PredictionEngine ou l'exportation du modèle vers un fichier binaire ou au format ONNX.
ML.NET fournit énormément de taches de machine learning différentes pour traiter et entrainer vos données. Ces taches sont divisées en 2 parties , les apprentissages supervisés et non supervisés :
Tâches d'apprentissage supervisé :
- Classification binaire : La tâche de classer les données dans l'une des deux classes possibles.
- Classification multiclasse : tâche consistant à classer les données dans l'une des différentes classes possibles.
- Régression : tâche consistant à prédire une variable de sortie continue en fonction des caractéristiques d'entrée.
- Classement : tâche consistant à classer une liste d'éléments en fonction de leur pertinence par rapport à une requête donnée.
- Recommandation : tâche consistant à recommander des éléments aux utilisateurs en fonction de leurs préférences.
Tâches d'apprentissage non supervisées :
- Regroupement : tâche consistant à regrouper des points de données similaires en fonction de leur similarité.
- Détection d'anomalies : tâche de détection de points de données inhabituels ou anormaux qui ne correspondent pas aux modèles normaux.
Nous avons également des algorithmes associés à chaque type d'entrainement qui peuvent être utilisés :
Modèle de classification binaire :
- FastTreeBinaryTrainer : un entraîneur de classification binaire qui utilise des arbres de décision.
- AveragedPerceptronTrainer : un entraîneur de classification binaire linéaire qui utilise l'algorithme de perceptron moyenné.
Modèle de classification multiclasse :
- OneVersusAllTrainer : un entraîneur de classification multiclasse qui utilise l'approche un contre tous avec n'importe quel entraîneur de classification binaire.
- LightGbmMulticlassTrainer : un entraîneur de classification multiclasse qui utilise le boosting de gradient et les arbres de décision.
Modèle de régression :
- FastTreeRegressionTrainer : un entraîneur de régression qui utilise des arbres de décision.
- LbfgsPoissonRegressionTrainer : un entraîneur de régression qui utilise l'algorithme de régression Poisson.
Modèle de clustering :
- KMeansTrainer : un entraîneur de clustering qui utilise l'algorithme K-means.
J'imagine que cela fait beaucoup d'informations d'un coup mais avec nous avons fait un tour d'horizon rapide de ML.NET , des concepts basiques du machine learning associés à ML.NET.
Je vous laisse vous entrainer et le code de l'application est disponible ici :
https://github.com/AlexCastroAlex/ML.NET.Sample.git
Have fun coding ! 😎

Alexandre CASTRO
.NET et Azure